
Chainlink recently announced a new technology: Block-STM. The robust and stable implementation accelerates smart contract execution and emanates from the Diem project. Block-STM is compatible with all existing blockchains, and requires no modification or adoption by miners.
What is Block-STM?
Block-STM is a parallel execution engine for smart contracts, built around the principles of Software Transactional Memory. Transactions are grouped in blocks, each block containing a pre-ordered sequence of transactions TX1, TX2, …, TXn. Transactions consist of smart-contract code that reads and writes to shared memory and their execution results in a read-set and a write-set: the read-set consists of pairs, a memory location and the transaction that wrote it; the write-set consists of pairs, a memory location and a value, that the transaction would record if it became committed.
Block-STM Origin: Parallel Execution & Software Transactional Memory Implementation In Database
An approach pioneered in the Calvin 2012 and Bohm 2014 projects in the context of distributed databases is the foundation of much of what follows. The insightful idea in those projects is to simplify concurrency management by disseminating pre-ordered batches (akin to blocks) of transactions along with pre-estimates of their read- and write- sets. Every database partition can then autonomously execute transactions according to the block pre-order, each transaction waiting only for read dependencies on earlier transactions in the block. The first DiemVM parallel executor implements this approach but it relies on a static transaction analyzer to pre-estimate read/write-sets which is time consuming and can be inexact.
Another work by Dickerson et al. 2017 provides a link from traditional database concurrency to smart-contract parallelism. In that work, a consensus leader (or miner) pre-computes a parallel execution serialization by harnessing optimistic software transactional memory (STM) and disseminates the pre-execution scheduling guidelines to all validator nodes. Later works, including ParBlockchain and OptSmart 2021 add read/write-set dependency tracking during pre-execution and disseminates this information to increase parallelism. Those approaches remove the reliance on static transaction analysis but require a leader to pre-execute blocks.
The Block-STM parallel executor combines the pre-ordered block idea with optimistic STM to enforce the block pre-order of transactions on-the-fly, completely removing the need to pre-disseminate an execution schedule or pre-compute transaction dependencies, while guaranteeing repeatability.
Technical overview
Block-STM is a parallel execution engine for smart contracts, built around the principles of Software Transactional Memory. Transactions are grouped in blocks, each block containing a pre-ordered sequence of transactions TX1, TX2, …, TXn. Transactions consist of smart-contract code that reads and writes to shared memory and their execution results in a read-set and a write-set: the read-set consists of pairs, a memory location and the transaction that wrote it; the write-set consists of pairs, a memory location and a value, that the transaction would record if it became committed.
Block pre-order
A parallel execution of the block must yield the same deterministic outcome that preserves a block pre-order, namely, it results in exactly the same read/write sets as a sequential execution. If, in a sequential execution, TXk reads a value that TXj wrote, i.e., TXj is the highest transaction preceding TXk that writes to this particular memory location, we denote this by:
TXj → TXk Running example
The following scenario will be used throughout this post to illustrate parallel execution strategies and their effects.
A block B consisting of ten transactions, TX1, TX2, ..., TX10,
with the following read/write dependencies:
TX1 → TX2 → TX3 → TX4
TX3 → TX6
TX3 → TX9To illustrate execution timelines, we will assume a system with four parallel threads, and for simplicity, that each transaction takes exactly one time-unit to process.
If we knew the above block dependencies in advance, we could schedule an ideal execution of block B along the following time-steps:
- Parallel execution of TX1, TX5, TX7, TX8
- Parallel execution of TX2, TX10
- Parallel execution of TX3
- Parallel execution of TX4, TX6, TX9
Optimistic Scheduling
What if dependencies are not known in advance? A correct parallel execution must guarantee that all transactions indeed read the values adhering to the block dependencies. That is, when TXk reads from memory, it must obtain the value(s) written by TXj, TXj → TXk, if a dependency exists; or the initial value at that memory location when the block execution started, if none.
Block-STM ensures this by employing an optimistic “speculate-validate-redo” approach, executing transactions greedily and optimistically in parallel and then validating, repeating if validation fails. Validation of TXk re-reads the read-set of TXk and compares against the original read-set that TXk obtained in its latest execution. If the comparison fails, TXk aborts and re-executes.
The key insight is that preordering greatly simplifies optimism!
- If validation fails, only higher transactions necessitate revalidation (VALIDAFTER)
- Reads obtain the value written by highest preceding transaction, not the last written value (READHIGH)
With this insight, we first consider a straightforward strawman approach. The strawman algorithm uses a centralized dispatcher that coordinates work by parallel threads.
Strawman (S-1) Algorithm
// Phase 1:
dispatch all TX’s for execution in parallel ; wait for completion
// Phase 2:
repeat {
dispatch all TX's higher than the last failed for read-set validation in parallel ; wait for completion
} until all read-set validations pass
read-set validation of TXj {
re-read TXj read-set
if read-set differs from original read-set of the latest TXj execution
re-execute TXj
}
execution of TXj {
(re-)process TXj, generating a read-set and write-set
}S-1 operates in two master-coordinated phases. Phase 1 executes all transactions optimistically in parallel. Phase 2 repeatedly validates all transactions higher than the last failed optimistically in parallel, re-executing those that fail, until there are no more read-set validation failures.
Recall our running example, a Block B with dependencies TX1 → TX2 → TX3 → {TX4, TX6, TX9}), running with four threads, each transaction taking one time unit (and neglecting all other computation times). A possible execution of S-1 over Block B would proceed along the following time-steps:
- Phase 1 starts. parallel execution of TX1, TX2, TX3, TX4
- Parallel execution of TX5, TX6, TX7, TX8
- Parallel execution of TX9, TX10
- Phase 2 starts. In the first loop iteration, parallel read-set validation of all transactions in which TX2, TX3, TX4, TX6 fail and re-execute
- Continued parallel read-set validation of all transactions in which TX9 fails and re-executes
- In the next phase-2 loop iteration, parallel read-set validations of all transactions in which TX3, TX4, TX6 fail and re-execute
- In the next phase-2 loop iteration, parallel read-set validations of all transactions in which TX4, TX6, TX9 fail and re-execute
- In the last phase-2 loop iteration, parallel read-set validations of all transactions succeed
The Block-STM Algorithm
In the full Block-STM solution, two fundamental improvements are introduced over the above strawman.
Task stealing. The first improvement is to replace both phases with parallel task-stealing by threads. It follows the insight from S-1, distinguishing between a preliminary execution (corresponding to phase 1) and re-execution (following a validation abort). Stealing is coordinated via two synchronization counters, one per task type, nextPrelimExecution (initially 1) and nextValidation (initially n+1).
Stealing enables validation of higher transactions to start immediately upon completion or when lower transactions fail validation. Every (re-)execution of TXj guarantees that read-set validation of all higher transactions will be dispatched by decreasing nextValidation back to j+1.
Primitive dependency tracking. The second improvement is an extremely simple dependency tracking (no graphs or partial orders) that considerably reduces aborts. When TXj aborts, the write-set of its latest invocation is marked ABORTED. Higher transactions simply suspend on reading ABORTED mark, waiting until a re-execution of TXj overwrites it. This is another demonstration of transaction pre-order simplifying matters substantially.
A high-level thread loop with task stealing is the following:
- if available, steal next validation task TXj
- else, steal next prelim-execution task TXj
Supporting dependency managements via ABORTED tagging and early re-validation of aborted tasks is done as follows:
- If validation fails, mark write-set ABORTED and immediately decrease nextValidation
- If a re-execution write-set different from original, decrease nextValidation again
A more precise description is given in (less than 20 lines of) the pseudo code below. For full details, see the whitepaper.
Block-STM Algorithm
// per thread main loop:
repeat {
task := "NA"
// if available, steal next read-set validation task
atomic {
if nextValidation < nextPrelimExecution
(task, j) := ("validate", nextValidation)
nextValidation.increment();
}
if task = "validate"
validate TXj
// if available, steal next execution task
else atomic {
if nextPrelimExecution <= n
(task, j) := ("execute", nextPrelimExecution)
nextPrelimExecution.increment();
}
if task = "execute"
execute TXj
validate TXj
} until nextPrelimExecution > n, nextValidation > n, and no task is still running
read-set validation of TXj {
re-read TXj read-set
if read-set differs from original read-set of the latest TXj execution
mark the TXj write-set ABORTED
atomic { nextValidation := min(nextValidation, j+1) }
re-execute TXj
}
execution of TXj {
(re-)process TXj, generating a read-set and write-set
resume any TX waiting for TXj's ABORTED write-set
if the new TXj write-set contains locations not marked ABORTED
atomic { nextValidation := min(nextValidation, j+1) }
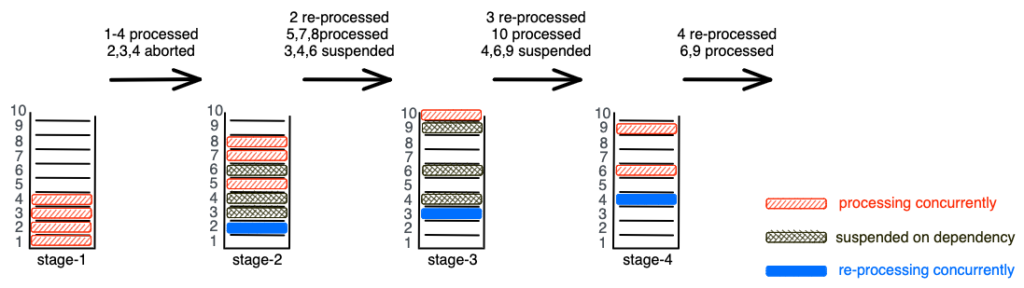
}Block-STM enhances efficiency through simple, on-the-fly dependency management using the ABORTED tag. For our running example of block B, an execution with four threads may be able to avoid several of the re-executions incurred in the strawman scenario by waiting on an ABORTED mark. Despite the high-contention B scenario, a possible execution of Block-STM may achieve very close to optimal scheduling as shown below. A possible execution over Block B (recall, TX1 → TX2 → TX3 → {TX4, TX6, TX9}) would proceed along the following time-steps (depicted in the figure):
- Parallel execution of TX1, TX2, TX3, TX4; read-set validation of TX2, TX3, TX4 fail; nextValidation set to 3
- Parallel execution of TX2, TX5, TX7, TX8; executions of TX3, TX4, TX6 are suspended on ABORTED; nextValidation set to 6
- Parallel execution of TX3, TX10; executions of TX4, TX6, TX9 are suspended on ABORTED; all read-set validations succeed (for now)
- Parallel execution of TX4, TX6, TX9; all read-set validations succeed
Correctness
Correct optimism revolves around maintaining two principles:
- READHIGH(k): Whenever TXk executes (speculatively), a read by TXk obtains the value recorded so far by the highest transaction TXj preceding it, i.e., where j < k. Higher transactions TXl, where l > k, do not interfere with TXk.
- VALIDAFTER(j, k): For every j,k, such that j < k, a validation of TXk’s read-set is performed every time TXj executes (or re-executes).
Jointly, these two principles suffice to guarantee both safety and liveness no matter how transactions are scheduled. Briefly, safety follows because a TXk gets validated after all TXj, j < k, are finalized. Liveness follows by induction. Initially transaction 1 is guaranteed to pass read-set validation successfully and not require re-execution. After all transactions from TX1 to TXj have successfully validated, a (re-)execution of transaction j+1 will pass read-set validation successfully and not require re-execution.
READHIGH(k) is implemented in Block-STM via a simple multi-version in-memory data structure that keeps versioned write-sets. A write by TXj is recorded with version j. A read by TXk obtains the value recorded by the latest invocation of TXj with the highest j < k.
The special value ABORTED may be stored at version j when the latest invocation of TXj aborts. If TXk reads this value, it suspends and resumes when the value becomes set.
VALIDAFTER(j, k) is implemented by scheduling for each TXj a read-set validation of TXk, for every k > j, after TXj completes (re-)executing. Interacting with early re-validation is slightly subtle. Suppose that TXj → TXk. Recall, when TXj fails, Block-STM immediately schedules (re-)validations of TXk, k > j, before TXj completes re-execution. There are two possible cases. If a TXk-validation reads an ABORTED value of TXj, it will wait for TXj to complete; and if it reads a value which is not marked ABORTED and the TXj re-execution has a new write-set, then TXk will be forced to revalidate again.
Benefits of Block-STM
Simplicity is a virtue of Block-STM, not a failing, enabling a robust and stable implementation. Through a careful combination of simple, known techniques and applying them to a pre-ordered block of transactions that commit at bulk, Block-STM:
- enables effective speedup of smart contract parallel processing
- enables repeatable execution (required)
- turns STM practical because of linear dependencies/validation
- commits at bulk per block (rather than per transaction)
- benefits clients independently
- can work with/over existing blockchains without requiring adoption by all/other validator nodes
Block-STM has been integrated within the Diem blockchain core (https://github.com/diem/) and evaluated on synthetic transaction workloads, yielding over 17x speedup on 32 cores under low/modest contention.
Via this site